226 - Database Final 2
Lec12: Distributed database
- no share physical component
- independent of each other
- Transaction may access data at one or more sites
Replication – multiple copies of data, stored in different sites, for faster retrieval and fault tolerance
Fragmentation – Relation is partitioned into several fragments stored in distinct sites
Data replication
- Full replication of a relation: relation stored at all sites
- Fully redundant databases: entire DB in every site
- Pros
- Availability: site failure is OK if replicas exist
- Parallelism: queries processed by several nodes in parallel
- Reduced data transfer: relation available locally at site w/ a replica
- Cons
- Increased cost of updates: update each replica
- Increased complexity of concurrency control: concurrent updates to distinct replicas
- One solution: choose one copy as primary copy
Horizontal fragmentation
–Partition a table horizontally
–A fragment == a subset of rows == shard
–A table is divided to one or more horizontal fragments
Vertical fragmentation
– Partition a table vertically
–A fragment == a subset of columns
–Ex: 2 vertical fragments of employee:
•(ssn, name, bdate, addr, sex), (ssn, salary, super_ssn, Dno)
–All fragments must contain a common candidate key (or superkey, or tuple-id)
Data Fragmentation
- Advantages:
- parallel processing on fragments of a relation
- Locality
Data transparency
User is unaware of details of how and where data is stored
• Fragmentation transparency
• Replication transparency
• Location transparency
Transaction coordinator:
- Start execution of txns that originate at the site
- Distribute sub-txns at sites for execution
- Coordinate termination of txn that originates at the site (commit or abort at all sites)
Transaction Manager
- Maintain log for recovery purposes
- Coordinate concurrent txn executing at this site
System Failure Modes
Network partition : A network is said to be partitioned when it has been split into two or more subsystems that lack any connection between them
-- Network partitioning and site failures are generally indistinguishable
Commit Protocol
Ensure atomicity across sites: a txn executing at multiple sites either be committed at all the sites, or aborted at all the sites
Two-phase commit (2PC) protocol: widely used
Phase 1 : Get a decision
Ci asks all participants to prepare to commit txn T
–Ci adds <prepare T> to (local) log and forces log to stable storage
–sends prepare T msg to all sites at which T executed
Upon receiving msg, txn manager at each site determines if it can commit T
–if not, add <no T> to log and send abort T msgto Ci
–if yes
•add <ready T> to log : A promise by a site to commit T or abort T
•force all logs for T to stable storage
•send ready T msg to Ci
Phase 2 : Record a decision
Ci waits for receiving responses from all participating sites, or timeout
• If Ci received a ready T msg from all participating sites, commit T else abort T
• Receiving just one abort T msg: good enough for Ci to abort T
Ci adds <commit T> or <abort T> to (local) log and forces log to stable storage
–Once on stable storage it is irrevocable(even if failures occur)
Ci sends the decision to each participant
–Each participant records <commit T> or <abort T> to log
Failure Handing
2PC Cons - coordinator failure may result in blocking, where a decision either to commit or to abort T may have to be postponed until Ci recovers
Site Failure
- Ci detects a site
- fails before the site responding w/ ready T msg: Ci assumes abort T msg
- fails after Ci receiving ready T msg: Ci ignores it ➜ have a promise
When site Sk recovers, it examines its log to determine fate of txns active at the time of the failure
–Log contains <commit T> record: redo (T)
–Log contains <abort T> record: undo (T)
–Log contains <ready T> record: consult Ci for the fate of T
–Log contains no control records (commit, abort, ready) concerning T:
➜ Sk failed before responding to prepare T msg from Ci : the failure of Sk precludes the sending of such a response, Ci must abort T➜ Sk must execute undo (T)
Coordinator Failure
If coordinator Cifails while the commit protocol for Tis executing then participating sites must decide on T’s fate:
- If an active site contains <commit T> in log ➜ commit T
- If an active site contains <abort T> in log ➜ abort T
- If some active participating site does not contain <ready T> in log, then the failed coordinator Ci cannot have decided to commit T : Can abort T; such a site must reject any subsequent <prepare T> message from Ci
- else, then all active sites must have <ready T> in their logs, but no additional control records (such as <abort T> of <commit T>) ➜ active sites must wait for Ci to recover, to find decision ➜ Blocking problem
Single lock manager
– a single lock manager resides in a single chosen site, say Si
– txn sends a lock request to Si and lock manager determines
- Txn can read data from any site w/ a replica of the data
- Writes must be performed on all replicas of a data item
- Pros: single implementation, simple deadlock handling
- Cons: bottleneck, vulnerability
Distributed lock manager
Local lock manager at each site; control access to local data items
- Pros: Simple implementation, reduce bottleneck, reduce vulnerability
- Cons: deadlock detection
Primary copy: choose one replica of data item to be the primary copy
–Site containing the replica is called the primary site for that data item=
- When a txn needs to lock a data item Q, it requests a lock at the primary site of Q
- Pros: simple implementation
- Cons: If the primary site of Q fails, Q is inaccessible even though other sites containing a replica may be accessible
Quorum Consensus Protocol :
- Each site is assigned a weight; S = the total of all site weights ➜ A more reliable site can get higher weight
Choose two values: read quorum QR and write quorum QW
–Rules: QR +QW > S and 2 *QW > S
Read: must lock enough replicas that sum(site weight) >= QR
- Write: must lock enough replicas that sum(site weight) >= QW
Pros: the cost of either read or write locking can be selectively reduced
•Optimize read: smaller QR, larger QW; optimize write: larger QR, smaller QW
Timestamp
Each transaction must be given a unique timestamp (TS)
– Each site generates a unique local TS using either a logical counter or the local clock
– Global unique TS: {unique local TS, unique site identifier}
Replication with Weak Consistency
- Replication of data with weak degrees of consistency (w/o guarantee of serializabiliy)
- i.e. QR +QW ≤S or 2*QW≤S
- Usually only when not enough sites are available to ensure quorum
- Tradeoffs: consistency, availability, latency/performance
- Key issues:
- Reads may get old versions
- Writes may occur in parallel, leading to inconsistent versions
Master-slave Replication
- txn updates: at a single “master” site, and propagated to “slave” sites
Update propagation -not part of txn
•immediately (after txncommits), or async(lazy, periodic)
–txnmay read from slave sites, but no update
–Replicas sees a transaction-consistent snapshot of DB at primary site
Multi-master replication
–txn updates done at any replica: update local copy, and system propagates to replicas transparently - txn unaware data replication
Lazy replication
–Txn updates: at one site (primary or any)
–Update propagation: lazy (not on critical path, after txn commits)
Deadlock detection: cannot be detected locally at either site
➜ Centralized detection: A global wait-for graph is constructed and maintained in a single site
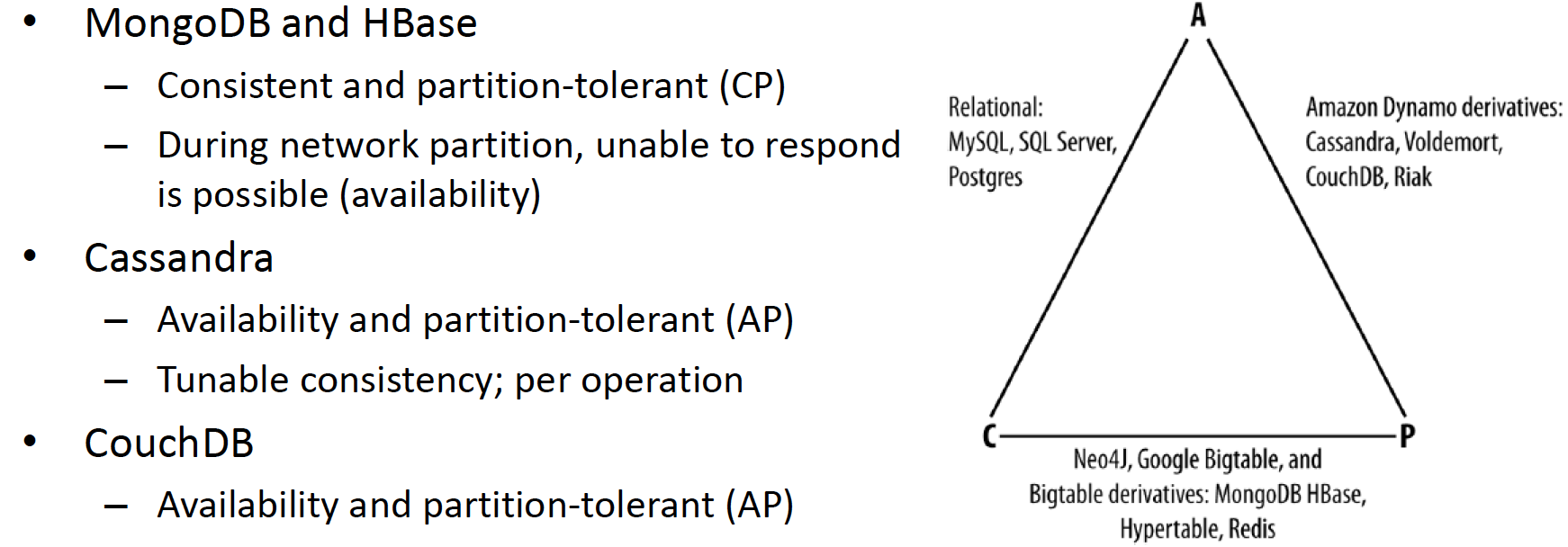
CAP
Availability : To be robust (ability of system to function even during failures)
➜ Detect failures, Reconfigure system, Recovery/Reintegration
Consistency:
● Strong consistency: serializable schedule
● Weak consistency: master-slave, multi-master, lazy replication, etc.
Tade-off between A and C
–Most of distributed consensus algorithms will block during partitions to ensure consistency
• Paxosdoes not block as long as a majority of participants are alive
–Many apps require continued operation even during network partition
• Even at the cost of consistency
Consistency: All copies have the same value
Availability: System can run even if parts have failed
Partition-tolerant: Survive network partitioning
★ It is impossible to achieve all three ➜ Any two can be achieved
★ CAP theorem only matters when there is a partition
Eventual Consistency
when no updates occur for a long period of time, eventually all updates will propagate through the system and all the nodes will be consistent
– You may not know how long it may take
• Known as BASE (Basically Available, Soft state, Eventual consistency)
Soft state: copies of a data item may be inconsistent
• Used by most NoSQL
Lec13 : No SQL
- Schema-less data stored as some form of key-value pair DB
- Scalability: scale out
- (usually) availability instead of consistency: CAP
- Eventual consistency (BASE)
| <b></b> | RDBMS | NoSQL |
|---|---|---|
| Type of data | structured data | Semi-and un-structured data |
| Organization of data | schema: tables/rows/columns | schema-less: key-value pairs |
| Design steps |
requirements➜ data model (ERD, UML) ➜ tables ➜… |
store data first➜ (transform data) ➜ get/put |
| data association | referential integrity, foreign keys | You are on your own |
| Functionality | complex | simple |
| Properties | ACID | BASE |
| Pros |
(strong) consistency Transactions Joins |
Schema-less Scalability, Availability Performance |
| Cons |
Scalability Availability |
Eventual consistency Tricky join No transactions |
- Simple architecture
- a unique identifier (key) maps to an obj(value)
- DB itself does not care about obj
- Good for
- Simple data model
- Scalability
- Bad for : “Complex” datasets
- Examples: AWS DynamoDB, Azure Tables, Google Cloud Datastore, Riak, Redis, Azure CosmosDB
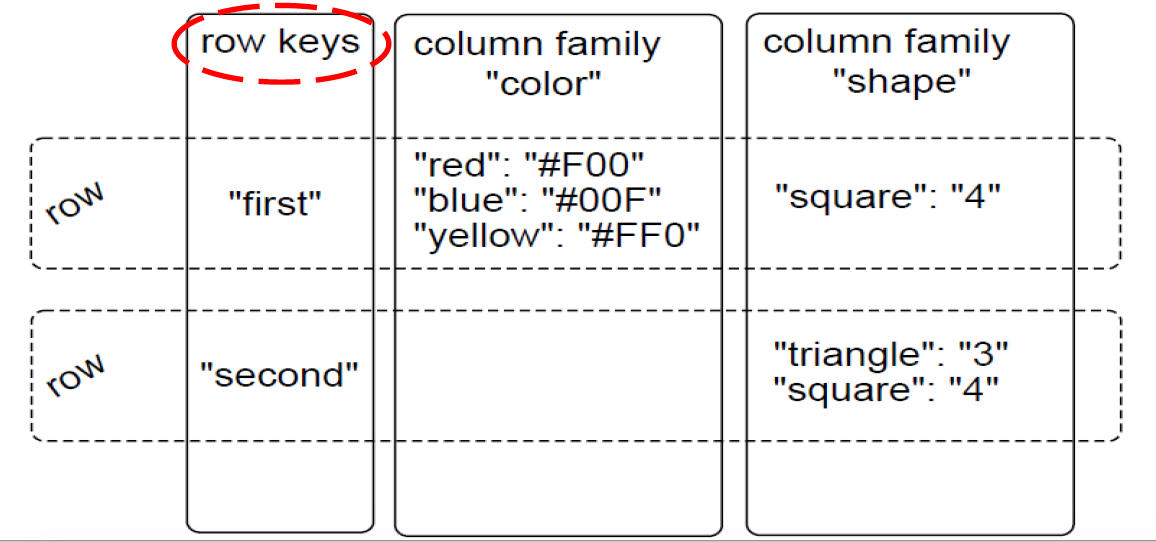
NoSQL–Column-family/BigTable
- Key-value pair + grouping
- Key –{a set of values}
- E.g., time series data from sensors, languages of web page
- Good for
- More complex data set (than simple key-value pair)
- Scalability
- Examples : Cassandra, HBase, Hypertable, Azure CosmosDB
NoSQL –Document
- DB knows the nature of the data
- Document –JSON
- Need index to improve performance
- Scalability –clustering, replication, some w/ partition-tolerant
- Good for
- Systems already using document-style data
- Scalability
- Examples: MongoDB, CouchDB, AWS DynamoDB, Azure CosmosDB
NoSQL–Graph
- How data is related and what calculation is to be performed
- Usually also has “transaction”
- Good for
- Interconnected Data and non-tabular
- Geospatial problems, recommendation engine, network analysis, bioinformatics
- “Closeness” of relationship
- How vulnerable a company is to “bad news” for another company
- Interconnected Data and non-tabular
- Bad for: Simple tabular data
- Examples: Neo4j, Azure CosmosDB
Cassandra
- Scalable High Availability NoSQL, key-value pair + column family (≈ table in RDBMS)
- Data model: a partitioned row store
- Rows are organized into tables
- Partition: consistent hashing - decides storage node (≈ AWS DynamoDB)
- adding/removing nodes in cluster only reshuffles keys among neighboring nodes
- Tunable consistency: decided by client apps, per operation
- Consistency level: 1, 2, 3, quorum, all, any, etc. (quorum ≈ AWS DynamoDB )
- W: sent to all replica, R: decided by consistency level
- Replication and multi-DC replication
- asynchronous masterless(peer-to-peer) replication
- Cassandra Query Language (CQL): SQL like
- No joins and subqueries
- materialized views (i.e. pre-computed results of queries)
HBase
- Column-oriented DB based on Google BigTable
- Distributed, (timestamp) versioned, NoSQL DB on top of Hadoop and HDFS
- Strong consistent reads and writes: not eventual consistency
- –All operations are atomic at the row level, regardless of # of columns
- Write ahead logging (WAL): protect from server failure
- Region-based storage architecture: a set of rows, [starting-row-key, ending-row-key)
- Auto sharding of tables
- HBaseMaster: masternode
- Assign regions to region servers
MongoDB
- Scalable distributed document DB
- Nested JSON document (binary form of JSON –BSON)
- A document: a JSON obj w/ key-value pairs ≈ row in RDBMS
- CRUD: JavaScript, ACID at document level
- No joins: still allow to retrieve data via relationship ➜ $lookup
- Replica Sets
- One server as primary (master), others as secondary (w/ replicated data)
- Client only reads from or writes to master
- Auto sharding – range-based, hash-based, user-defined
CouchDB
- JSON-and REST-based document-oriented DB]
- Each document
- Unique immutable _id: auto-gen or explicit assigned per doc
- _rev: revision per doc, starting from 1, auto-modified after doc changes
- Each update/delete must specify both_id and _rev
- CRUD: Futon web interface
- No transaction, No locking
- View: Content generated by mapreduce functions incrementally
- Changes API
- Multi-master replication: HA
NoSQL Pros and Cons
Pros:
–schema-less
–scalability (scale out), availability
–performance
–simpler change management (“agile”, faster dev)
Cons:
–eventual consistency
–tricky (server-side) join
–no transaction
–schema-less
Trade-offs (w/ RDBMS): functionality, availability, consistency, durability, scalability, performance