226 - (Note)Database
A NoSQL (originally referring to "non SQL" or "non relational") database provides a mechanism for storage and retrieval of data that is modeled in means other than the tabular relations used in relational databases.
- Simplicity of design
- Simpler "horizontal" scaling to clusters of machines : Scale out
- Finer control over availability
Scale horizontally (or scale out/in) means to add more nodes to (or remove nodes from) a system, such as adding a new computer to a distributed software application, such as adding a new computer to a distributed software application.
Scale vertically (or scale up/down) means to add resources to (or remove resources from) a single node in a system, typically involving the addition of CPUs or memory to a single computer.
NoSQL v.s. Relational Database, company all use mixture of database
ERD : An entity–relationship model (ER model for short) describes interrelated things of interest in a specific domain of knowledge. A basic ER model is composed of entity types (which classify the things of interest) and specifies relationships that can exist between instances of those entity types.
Database Schema : The database schema of a database system is its structure described in a formal language supported by the database management system (DBMS). The term "schema" refers to the organization of data as a blueprint of how the database is constructed (divided into database tables in the case of relational databases).
Difference between schema and model
A schema is a blueprint of the database which specifies what fields will be present and what would be their types. For example an employee table will have an employee_ID column represented by a string of 10 digits and an employee_Name column with a string of 45 characters.
Data model is a high level design implementation which decides what can be present in the schema. It provides a database user with a conceptual framework in which we specify the database requirements of the database user and the structure of the database to fulfill these requirements.
Three-schema approach
The three-schema approach provides for three types of schemas with schema techniques based on formal language descriptions:
- External schema for user views
- Conceptual schema integrates external schemata : (It typically includes only the main concepts and the main relationships among them. Typically this is a first-cut model, with insufficient detail to build an actual database. This level describes the structure of the whole database for a group of users.)
- Internal schema that defines physical storage structures
ER diagram
https://creately.com/blog/diagrams/er-diagrams-tutorial/
derived attributes
A derived attribute is an attribute whose value is calculated (derived) from other attributes.
Schema
A schema is a collection of database objects (as far as this hour is concerned—tables) associated with one particular database username. This username is called the schema owner, or the owner of the related group of objects. You may have one or multiple schemas in a database.
Relation table at most has one primary key, it does not have to have a primary key
foreign key(a,b) references (x,y) : composite foreign key
alter table after create department and employee table
alter table department add
foreign key (mgrssn) references employee(ssn);
to prevent circular definition
WHERE Address LIKE '%Huston,TX%';
WHERE Address not LIKE '%Huston,TX%';
not WHERE Address LIKE '%Huston,TX%';
BETWEEN 3000 AND 4000 => where salary >= 3000 AND salary <= 4000
select * from t1 where b+1 in (select c from t2 where c >a)
select * from t1 where exists(select c from t2 where c>a and b+1=c)
STUDENT
ID Name AGE
1 Ram 12
2 Sam 13
Above is an example of a table called Student having 2 rows (1,Ram,12) and (2,Sam,13) . Using this we can understand the difference.
Entity
It is something which has real existence. Like tuple1 contains information about Ram(id, name and Age) which has existence in real world . So the tuple1 is an entity. So we may say each tuple is an entity.
Entity Type
It is collection of entity having common attribute. As in Student table each row is an entity and have common attributes. So STUDENT is an entity type which contains entities having attributes id, name and Age.Also each entity type in a database is described by a name and a list of attribute.So we may say a table is an entity type
Entity SET
It is a set of entities of same entity type. so a set of one or more entities of Student Entity type is an Entity Set.
chained ops via triggers
triggers disadvantage: performance, because even your first execution didn't insert/delete any row, however the trigger still evoke other executions sequentially.
Midterm
a. update
update PersonID
set PersonID = PersonID + 1000
where PersonID in (select OwnerID from Car where brand = 'BMW');
b. contains 'n'
select Name, count(CarID)
from Perdon left join Car on Person.ID = Owner.Id
where Name like '%n_'
group by Name;
c. [use EXIST] does not own car and city is unknown
select Name
from Person
where City IS NULL AND NOT EXISTS(
select *
from Car
where OwnerID = PersonID)
order by Name DESC;
d. [use IN] more than two cars, at least one of which is BMW
select Name
from Person
where PersonID IN (
select OwnerID
from Car
Group by OwnerID
Having count(*)>2)
and PersonID IN(
select OwnerID
from Car
where brand = 'BMW');
e. living in NewWork
select PersonID, Name, Count(UNIQUE Brand)
from Person Join Car
where City = 'New Yotk'
Group by PersonID, Name
Normalization Form
http://dotnetanalysis.blogspot.com/2012/01/database-normalization-sql-server.html
Concurrency
Conflict in DBMS can be defined as two or more different transactions accessing the same variable and atleast one of them is a write operation.
For example:
T1: Read(X)
T2: Read (X)
In this case there's no conflict because both transactions are performing just read operations.
But in the following case:
T1: Read(X)
T2: Write(X)
there's a conflict.
Lets say we have a schedule S, and we can reorder the instructions in them. and create 2 more schedules S1 and S2.
Conflict equivalent: Refers to the schedules S1 and S2 where they maintain the ordering of the conflicting instructions in both of the schedules. For example, if T1 has to read X before T2writes X in S1, then it should be the same in S2 also. (Ordering should be maintained only for the conflicting operations).
Conflict Serializability: S is said to be conflict serializable if it is conflict equivalent to a serial schedule (i.e., where the transactions are executed one after the other).
Project 1
Replicated Data Consistency Explained Through Baseball
https://zhuanlan.zhihu.com/p/33264546
Read Performance: how long you might take to get the value of data
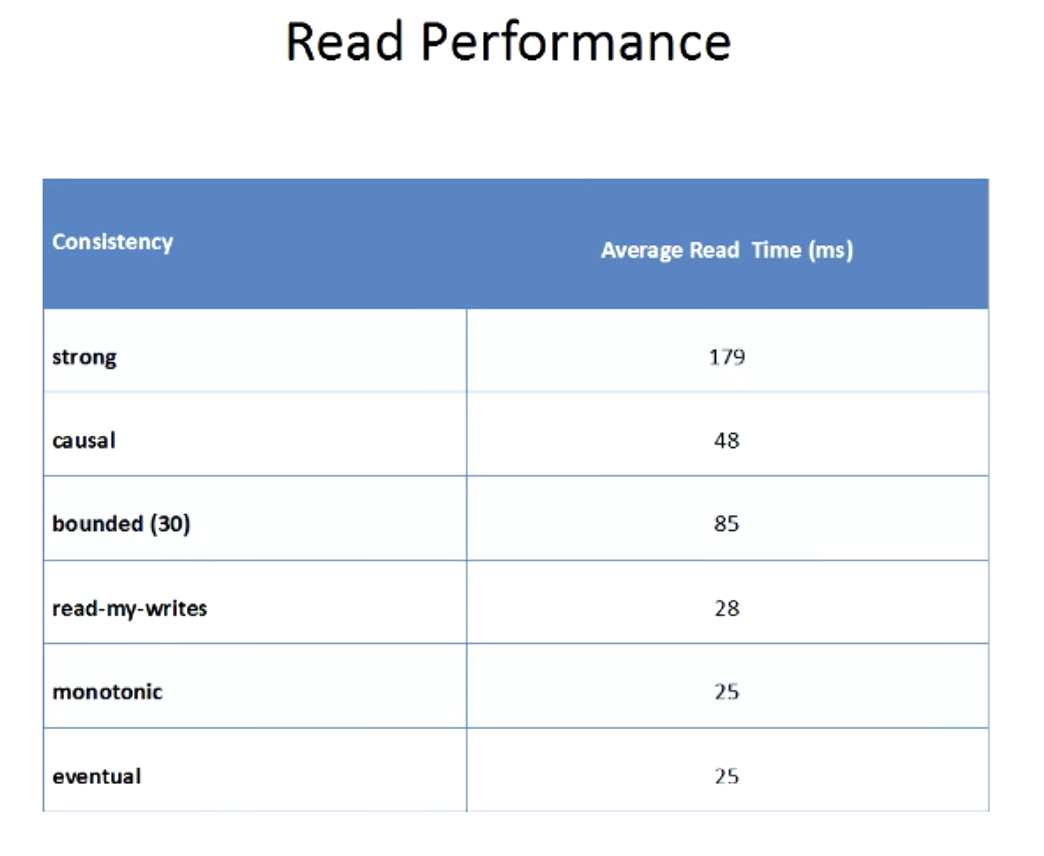
Reading Your Own Writes
如果数据是读多写很少的,比如一条评论等,可以写入 leader,然后从 follower 读取。异步复制中有个问题,如果用户在写入之后很快就读取,这时候数据可能还没复制到 follower,对用户而言数据好像丢失了。这个时候需要 read-after-consistency(read-your-writes consistency),保证用户在更新数据后刷新页面,能立刻看到他们的更新,但是不能保证其他用户的。 以下是一些实现方式:
- 当读取用户可能修改过的数据的时候,从 leader 读,否则从 follower 读取。总是从 leader 读取用户个人信息之类的东西,其他的从 followers 读。
- 跟踪数据变更时间,在更新的后一分钟内都从 leader 读取。
- 客户端记住最近的更新时间戳,然后系统可以从有该时间戳以后更新数据的 replica 读取,或者等待直到更新了数据。
- 如果数据中心分布在不同地理位置,请求必须路由到有改 leader 的数据中心读取。
更麻烦的是跨设备读取,比如在移动设备上更新了数据,在其他设备上要能看到更新。
Monotonic Reads
第二个异步复制会出现的问题是用户可能会看到某些数据『时间倒流』,从不同的 replica 中读取数据可能遇到。 Monotonic Reads: 每个用户的读取都只从一个 relica 读。比如基于用户 id hash 来选取 replica 读取。
Consistent Prefix Reads
第三个异步复制会碰到的反常的地方是:如果有些分片复制速度比其他慢,一个观察者可能会先看到回答,后看到问题(因果错乱)。 避免这种反常的方式是:consistent prefix reads. 如果一系列写入操作按照确定顺序执行,其他人读取这些写入结果以相同顺序出现。
保证写入操作有关联方都写入同一个 partition