Data structure
HashMap
The HashMap class is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls. This class makes no guarantees as to the order of the map.
- Initial capacity The capacity is the number of buckets in the hash table, The initial capacity is simply the capacity at the time the hash table is created.
- Load factor The load factor is a measure of how full the hash table is allowed to get before its capacity is automatically increased.
put:
- HashMap will hash the key and calculate its index
- if it is nor collided with other keys, then put in the bucket
- if it is collided, then it will put in back of the collided one as the linked list or balanced tree
- it the key is order in the map, then replace the value
- if the number of element exceeds the capacity * load factor, the map will resize itself
HashMap v.s. HashTable
Hashtableis synchronized, whereasHashMapis not. This makesHashMapbetter for non-threaded applications, as unsynchronized Objects typically perform better than synchronized ones.Hashtabledoes not allownullkeys or values.HashMapallows onenullkey and any number ofnullvalues.
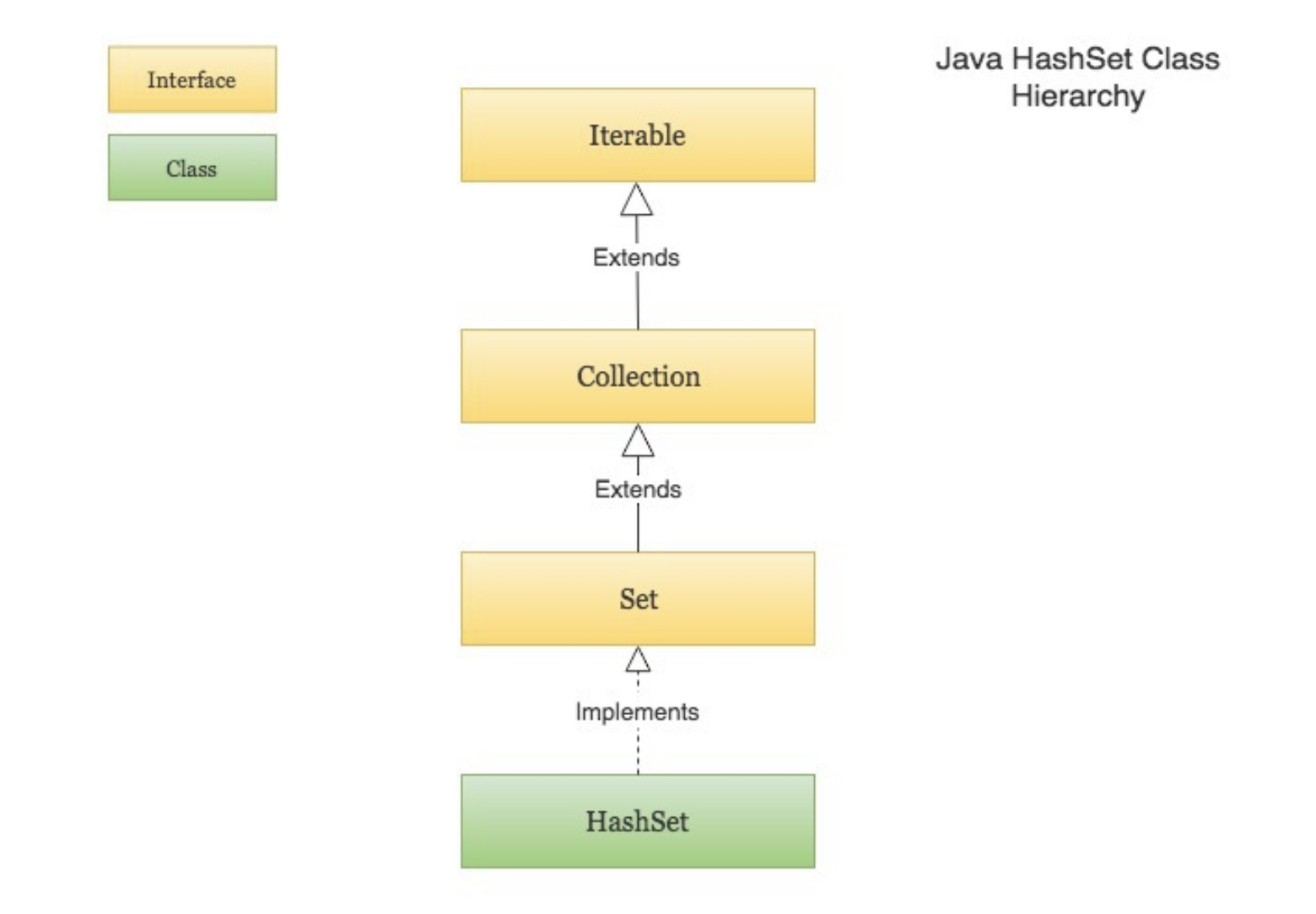
HashSet
HashSet internally uses a HashMap to store its elements.
HashSet is not thread-safe. If multiple threads try to modify a HashSet at the same time, then the final outcome is not-deterministic. You must explicitly synchronize concurrent access to a HashSet in a multi-threaded environment
HashSet doesn't allow null
Tree
tree structure or tree diagram is a way of representing the hierarchical nature of a structure in a graphical form.
In computer science, a tree is a widely used abstract data type —or data structure implementing this ADT—that simulates a hierarchical tree structure, with a root value and subtrees of children with a parent node, represented as a set of linked nodes.
TreeSet
TreeSet is similar to HashSet except that it sorts the elements in the ascending order while HashSet doesn’t maintain any order. TreeSet allows null element but like HashSet it doesn’t allow.
add, first(), last() pollFirst(), pollLast()
TreeMap
TreeMap is Red-Black tree based NavigableMap implementation. (BST) It is sorted according to the natural ordering of its keys.
- For operations like add, remove, containsKey, time complexity is O(log n) where n is number of elements present in TreeMap.
- TreeMap always keeps the elements in a sorted(increasing) order, while the elements in a HashMap have no order. TreeMap also provides some cool methods for first, last, floor and ceiling of keys.
ceilingKey(K key) Returns the least key greater than or equal to the given key, or null if there is no such key.
floorKey(K key) Returns the greatest key less than or equal to the given key, or null if there is no such key.
higherKey(K key) Returns the least key strictly greater than the given key, or null if there is no such key.
lowerKey(K key) Returns the greatest key strictly less than the given key, or null if there is no such key.
Trie
Trie is an ordered tree data structure that is used to store a dynamic set or associative array where the keys are usually strings.
Using Trie, search complexities can be brought to optimal limit (key length). If we store keys in binary search tree, a well balanced BST will need time proportional to
$$M * log N$$
, where M is maximum string length and N is number of keys in tree. Using Trie, we can search the key in O(M) time.
The basic form is that of a linked set of nodes, where each node contains an array of child pointers, one for each symbol in the alphabet (so for the English alphabet, one would store 26 child pointers and for the alphabet of bytes, 256 pointers). This is simple but wasteful in terms of memory
// Trie node struct TrieNode {
struct TrieNode *children[ALPHABET_SIZE];
// isEndOfWord is true if the node represents end of a word
bool isEndOfWord;
};
Dequeue
A linear collection that supports element insertion and removal at both ends.
The name deque is short for "double ended queue" and is usually pronounced "deck".
LinkedHashMap
HashMap in Java provides quick insert, search and delete operations. However it does not maintain any order on elements inserted into it. If we want to keep track of order of insertion, we can use LinkedHashMap.
LinkedHashMap is like HashMap with additional feature that we can access elements in their insertion order.
LinkedHashMap() Constructs an empty insertion-ordered LinkedHashMap instance with the default initial capacity (16) and load factor (0.75).
LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
Constructs an empty LinkedHashMap instance with the specified initial capacity, load factor and ordering mode.
The load factor is a measure of how full the hash table is allowed to get before its capacity is automatically increased.
"true for access-order, false for insertion-order"
protected boolean removeEldestEntry(Map.Entry<K,V> eldest)
Returns true if this map should remove its eldest entry.
Iterator
Iterators are used in Collection framework in Java to retrieve elements one by one. There are three iterators.
Enumeration : It is an interface used to get elements of legacy collections(Vector, Hashtable).
Iterator: It is a universal iterator as we can apply it to any Collection object. By using Iterator, we can perform both read and remove operations.
Iterator must be used whenever we want to enumerate elements in all Collection framework implemented interfaces like Set, List, Queue, Deque and also in all implemented classes of Map interface. Iterator is the only cursor available for entire collection framework.
Iterator object can be created by calling iterator() method present in Collection interface.
// Here "c" is any Collection object. itr is of
// type Iterator interface and refers to "c"
Iterator itr = c.iterator();
Iterator interface defines three methods:
// Returns true if the iteration has more elements
public boolean hasNext();
// Returns the next element in the iteration
// It throws NoSuchElementException if no more element present
public Object next();
// Remove the next element in the iteration
// This method can be called only once per call to next()
public void remove();
ListIterator: It is only applicable for List collection implemented classes like arraylist, linkedlist etc. It provides bi-directional iteration.
designing custom data structures
To implement an iterable data structure, we need to:
- Implement Iterable interface along with its methods in the said Data Structure
- Create an Iterator class which implements Iterator interface and corresponding methods.
class CustomDataStructure implements Iterable<> {
// code for data structure
public Iterator<> iterator() {
return new CustomIterator<>(this);
}
}
class CustomIterator<> implements Iterator<> {
// constructor
CustomIterator<>(CustomDataStructure obj) {
// initialize cursor
}
// Checks if the next element exists
public boolean hasNext() {
}
// moves the cursor/iterator to next element
public T next() {
}
// Used to remove an element. Implement only if needed
public void remove() {
// Default throws UnsupportedOperationException.
}
}