226 - Database (SQL)
Lec5 : SQL
Structured Query Language (SQL) :
SQL = DDL + DML
DDL is Data Definition Language : it is used to define data structures.
For example, with SQL, it would be instructions such as create table, alter table, drop table
DML is Data Manipulation Language : it is used to manipulate data itself.
For example, with SQL, it would be instructions such as select, insert, update, delete
| ERD | Relational Model | RDBMS | Object |
|---|---|---|---|
| Entity or Entity Type | Relation | Table | Class |
| Attribute | Attribute | Column | Property |
| Entity instance | Tuple | Row | Object |
Schema:
– A container object
– Elements within the container
• Tables, constraints, views, stored procedures, domains, etc.
Catalog (or “database” in MS SQL, MySQL)
– Collection of schemas
CREATE DATABASE COMPANY;
– INFORMATION_SCHEMA: special schema per catalog
• Information on all schemas in catalog: element descriptions
• self-describing
MySQL: Database == Schema
- Base tables – Created through the CREATE TABLE statement – Rows: persistent data storage
- Virtual tables –Created through the CREATE VIEW statement ★ May or may not have persistent data storage
- Derived tables A derived table is obtained from one or more other tables as the result of a subquery. **–Functionally equivalent to nested query –Temporarily exists in FROM** of a query ★ Not a DB object
★ Some foreign keys may cause error due to ① circular references ② referencing to non-existent tables ===== > CREATE TABLE w/o FK and then ALTER TABLE later
Column Data Types
| Data Type | Content |
|---|---|
| Numeric | INTEGER, INT, and SMALLINT |
| Floating-point (real) | FLOAT or REAL, and DOUBLE PRECISION |
| Character-string | CHAR(n), CHARACTER(n), VARCHAR(n), CHAR VARYING(n),CLOB |
| Bit-string | BIT(n), BIT VARYING(n), BLOB |
| Boolean | TRUE or FALSE or NULL |
| DATE | YYYY-MM-DD |
| TIME | HH:MM:SS |
| Timestamp | DATE and TIME |
| INTERVAL | Specifies a relative value, used to increment or decrement an absolute value of a data, time, or timestamp |
Domain (PostgreSQL) or Type (MS SQL, Oracle)
▻ Used as if it is a data type ▻ Improves schema readability: easier to change the data type for a domain that is used by numerous columns
CREATE DOMAIN SSN_TYPE AS CHAR(9);
CREATE TABLE (…, Ssn SSN_TYPE NOT NULL, …);
MySQL does not support this
Constraints and Defaults
● [NOT NULL | NULL] : missing means NULL; Column level only
● Default value :Column level only
DEFAULT<value>
● CHECK clause: apply to individual row; Column level or table level
Dnumber INT NOT NULL CHECK(Dnumber>0 AND Dnumber<21);
CHECK(Dept_create_date<= Mgr_start_date);
**CHECK** clause within Domain
CREATE DOMAIN DNUM AS INTEGER CHECK(D_NUM>0 AND D_NUM<10);
● PRIMARY KEY clause: one or more columns (composite PK)
–Column level or table level; ★At most one PK per table
Dnumber INT PRIMARY KEY
● UNIQUE clause: alternate (secondary) keys
–Column level or table level; 0 or more per table
Dname VARCHAR(15) UNIQUE;
CREATE TABLE X (…, UNIQUE(colA, ColB), …);
Referential Integrity Constraints
● FOREIGN KEY clause
★ Value of FK col in referencing table == value of PK in referenced table
★ Value of FK col can be NULL if col is nullable(no referential check)
–Default operation: reject insert/update/delete on violation
–Optional: referential triggered action clause
★ ON DELETE and ON UPDATE
• Options include SET NULL, CASCADE, and SET DEFAULT
★ CASCADE option suitable for “relationship” tables
[CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (col_name, ...)
REFERENCES tbl_name (col_name,...)
[ON DELETE reference_option]
[ON UPDATE reference_option]
reference_option:
RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT
Constraint name: useful for altering later
If the FOREIGN KEY clause included a CONSTRAINT name when you created the foreign key, you can refer to that name to drop the foreign key. Otherwise, the fk_symbol value is generated internally when the foreign key is created.
SQL allows a table to have two or more rows that are identical in all their column values ★ No PK is OK • Unlike relational model
SELECT-FROM-WHERE
Retrieve some columns from rows satisfying a condition
SELECT <column list>
SELECT <column list>
FROM <table list>
[ WHERE <condition> ] ;
<column list>: a list of columns (from <table list>) whose values are to be retrieved by the query, **i.e., projection<table list>: a list of the tables required to process the query<condition>: a conditional (Boolean) expression (selection condition**)
•May include logical comparison operators: =, <, <=, >, >=,and <>
–w/o WHERE: return all rows
Logical query processing steps:
★ FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER
★ **Actual query processing steps - query optimization
AS qualifier
Same column names may be used in different tables
☞ must qualify the column name with the table name
Column ambiguity can arise when queries that refer to the same table twice
☞ Alias is required
Use qualifier AS followed by desired new name
–Rename any column in the result of a query
–Logical rename for the duration of the query execution
Derived table
SELECT Y.c, Y.d
FROM (SELECT a AS c, b AS d FROM X) AS Y
WHERE ...
Unspecified WHERE Clause
Missing WHERE clause
–Indicates no condition on row selection
CROSS PRODUCT
–All possible row combinations among tables in FROM
SELECT ssn, dname
FROM company.employee, company.department;
Use of the Asterisk
SELECT * FROM …
–Retrieve all the column values of the selected rows
Table as Multi-set
★ duplicate rows can appear more than once
★ SQL does not automatically eliminate duplicate rows
SELECT DISTINCT: Only distinct rows remain
UNION, INTERSECT, EXCEPT
| Set : no duplicates | Multi-set : may have dup |
|---|---|
| s1 UNION s2 | s1 UNION ALL s2 |
| s1 INTERSECT s2 | s1 INTERSECT ALL s2 |
| s1 EXCEPT s2 | s1 EXCEPT ALL s2 |
Substring Pattern Matching
● LIKE comparison operator
–String pattern matching
–%: arbitrary number of zero or more characters
–underscore (_) : a single character
–% and _ can be escaped : ‘AB\_CD\%EF’ ESCAPE ‘\’
select fname,lname
from employee
where address LIKE '%Houston, TX%';
/* Not Like */
where Address not LIKE '%Huston,TX%';
Arithmetic Operators, Between
● Standard arithmetic operators: +, -, *, /
Show the resulting salaries if every employee working on the ProductX project is given a 10% raise.
select fname,lname,1.1*salary as increased_sal
from employee,works_on,project
where ssn=essn and pno=pnumber and pname='ProductX';
● BETWEEN
Retrieve all employees in department 5 whose salary is between $30,000 and $40,000
select *
from employee
where dno=5 and (salary between 30000 and 40000);
/*OR*/
where salary >= 30000 AND salary <= 40000
Ordering of Query Results -- ORDER
- DESC: result set in descending order
- ASC: result set in ascending order (deafult)
ORDER BY D.Dname DESC, E.Lname ASC, E.Fname ASC
Retrieve a list of employees and the projects they are working on, ordered by department and, within each department, ordered alphabetically by last name, first name
select dname,lname,fname,pnamef
from department,employee,works_on,project
where dnumber=dno and ssn=essn and pno=pnumber
order by dname,lname,fname;
INSERT
Specify a table name and a list of values for the row
- w/o column names : the same order as CREATE TABLE
- w/ column name and Columns not specified in INSERT ➜ DEFAULT or NULL
INSERT INTO company.EMPLOYEE (fname, lname, Dno, Ssn)
VALUES('Richard', 'MArani',4,'43142');
Insertion rejected when violating any constraint
UPDATE
Modify column values of existing rows in a table
–SET: specifies columns to be modified and new values
- w/o WHERE: update all rows
- w/ WHERE: update only selected rows (nested query, etc)
UPDATE EMPLOYEE
SET Salary = Salary * 1.1
WHERE Dno = 5;
Update rejected when violating any constraint, unless “ON UPDATE …” option specified in FK.
| Violation possible? | INSERT | UPDATE | DELETE |
|---|---|---|---|
| Domain constraint | Y | Y | N |
| Key constraint | Y | Y | N |
| Entity integrity constraint | Y | Y | N |
| Referential integrity constraint | Y | Y | Y |
Lec 6 : MORE SQL
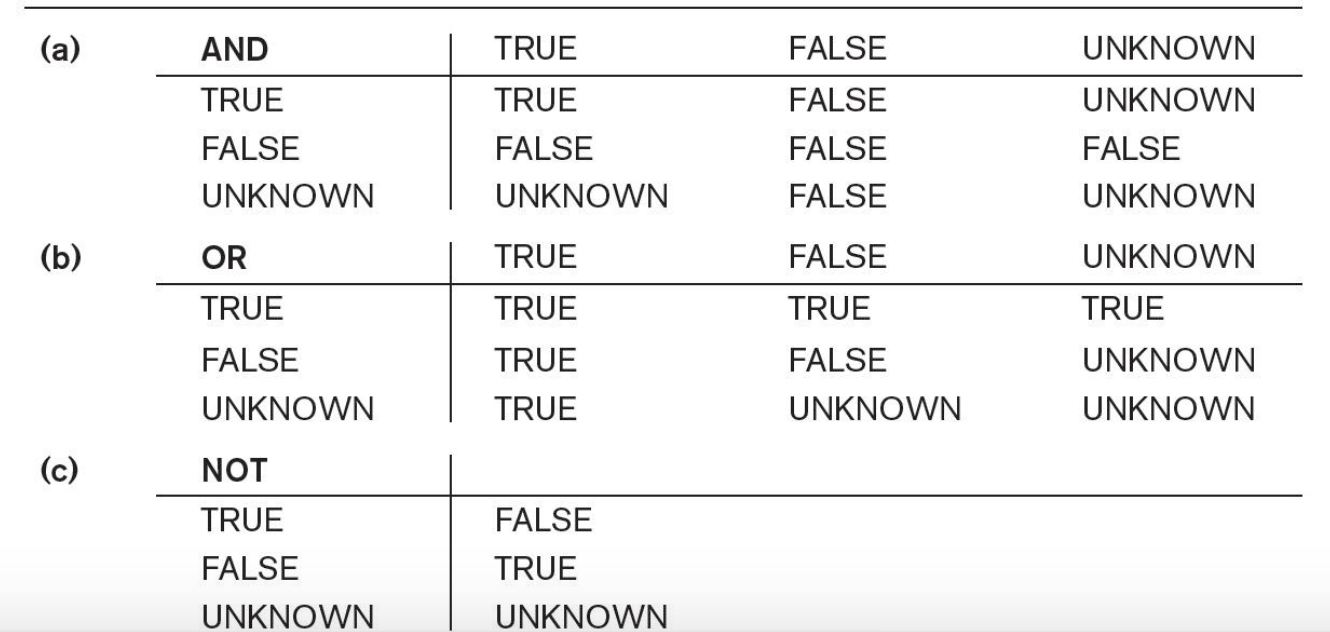
NULL
NULL: unknown, not applicable
Three-values logic:
Check if a column value is NULL
–ColName IS NULL
–ColName IS NOT NULL
– NOT (ColName IS NULL)
–Using =, <>, !=with NULL is not correct
–Not correct: ColName IS 'DAVID'
Retrieve the names of all employees who do not have a supervisor
select fname,lname
from employee
where superssn is null;
Nested queries
(or sub-queries)
–Inner query: a separate select-from-where block within WHERE clause of another (outer) query
★ May reference outer query’s column(s) (correlated nested query)
–Outer query
★ Can not reference inner query’s column
–Glue between inner query and outer query: IN, EXISTS
• Can be used in SELECT, UPDATE, DELETE
–Can be nested into multiple levels
IN
SELECT … WHERE v IN (Q)
Compares expression v with the result set of Q
–Evaluates to TRUE if v is a member in the result set of Q
–Q can be a complete SELECT statement
SELECT ...
FROM ...
WHERE Pho IN (SELECT proj_no FROM...);
–Q can be explicit set of values
SELECT … FROM … WHERE Name IN('Bob', 'David');
UPDATE T SET a = a + 10 WHERE b IN(Q)
DELETE T WHERE b IN(Q)
★ C IN (v1, v2) is equivalent to (C = v1 OR C = v2)
★ C NOT IN (v1, v2)is equivalent to (C != v1 AND C != v2)
SELECT … WHERE v = (Q)
–Returns TRUE if v is equal to the single value from Q
SELECT … WHERE v = SOME (Q)
–Returns TRUE if v equals to some value in the result set Q
–SOME is equivalent to ANY
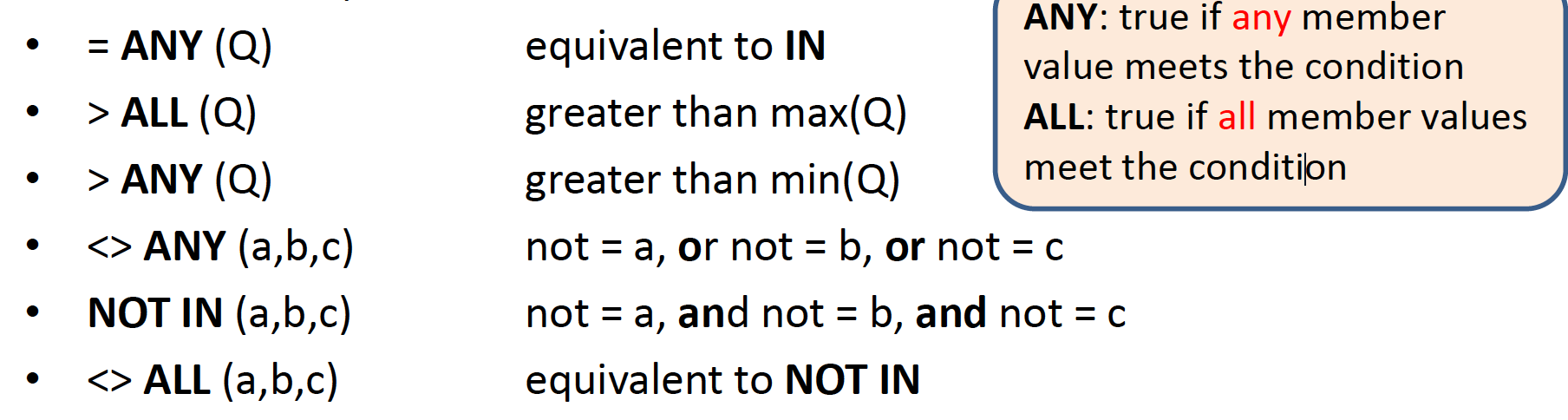
Retrieve the name of each employee who has a dependent with the same first name and same sex as the employee
select e.fname,e.lname
from employee as e
where e.ssn in (select essn
from dependent
where e.fname=dependent_name and e.sex=sex);
★ Def: Inner query references columns from outer query
★ Logically evaluated once for each row in the outer query
EXISTS
SELECT … WHERE EXISTS(Q)
–Check if the result of query Q is empty or not
★ Q returns at least one row ➜ TRUE
★ Empty result set from Q ➜ FALSE
★ Inner query usually references outer query’s columns
• Else there is no correlation between inner and outer queries
SELECT … WHERE NOT EXISTS(Q)
UPDATE T SET a = a + 10 WHERE EXISTS(Q)
DELETE T WHERE EXISTS(Q)
List the names of managers who have at least one dependent.
select fname,lname
from employee
where exists (select * from department where ssn=mgrssn) and
exists (select * from dependent where ssn=essn);
Retrieve the names of each employee who works in all projects controlled by department 5
select fname,lname
from employee
where NOT exists ((select Pnumber from PROJECT where Dnum=5)
EXCEPT (select Pno from WORKS_ON where Ssn = Essn));
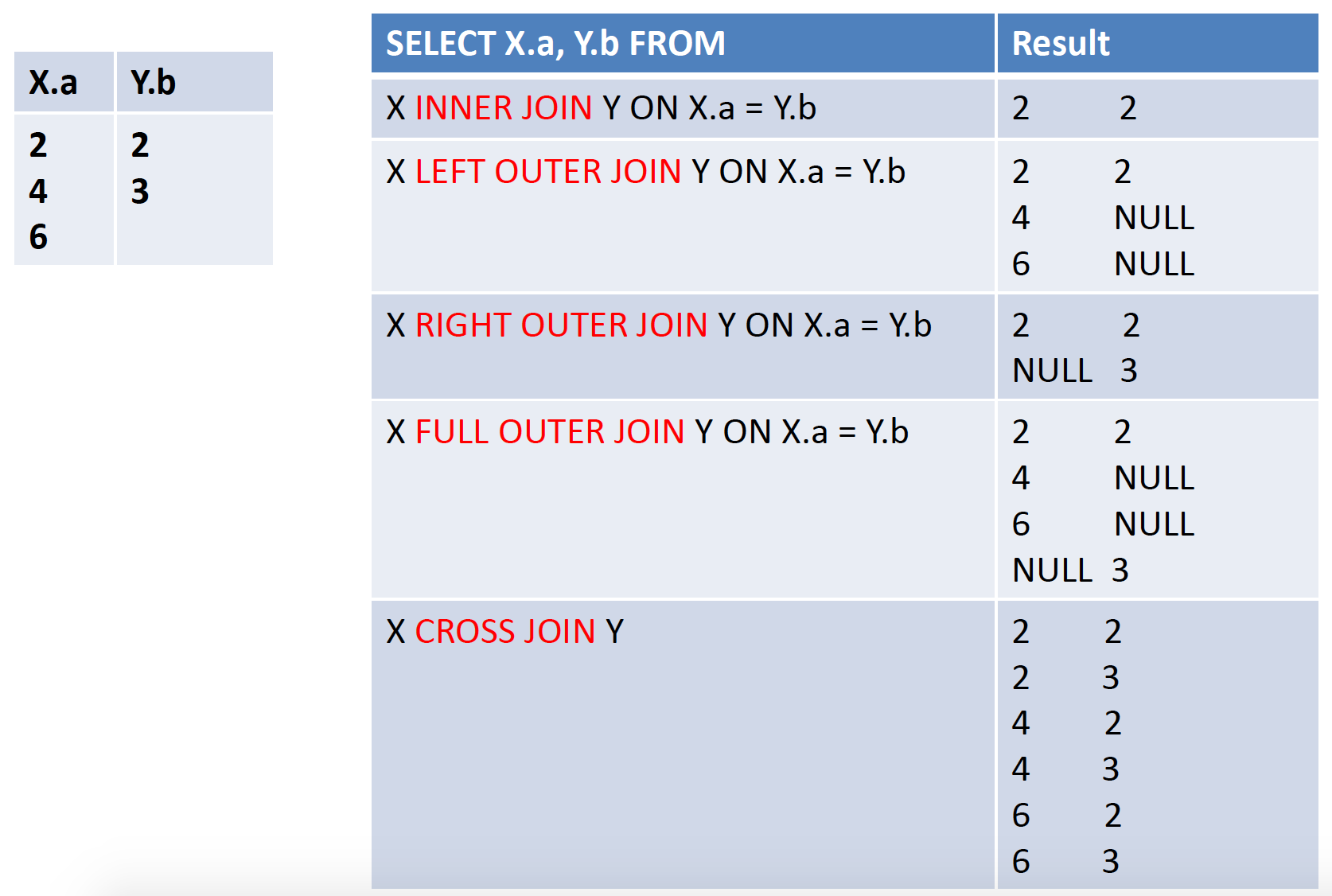
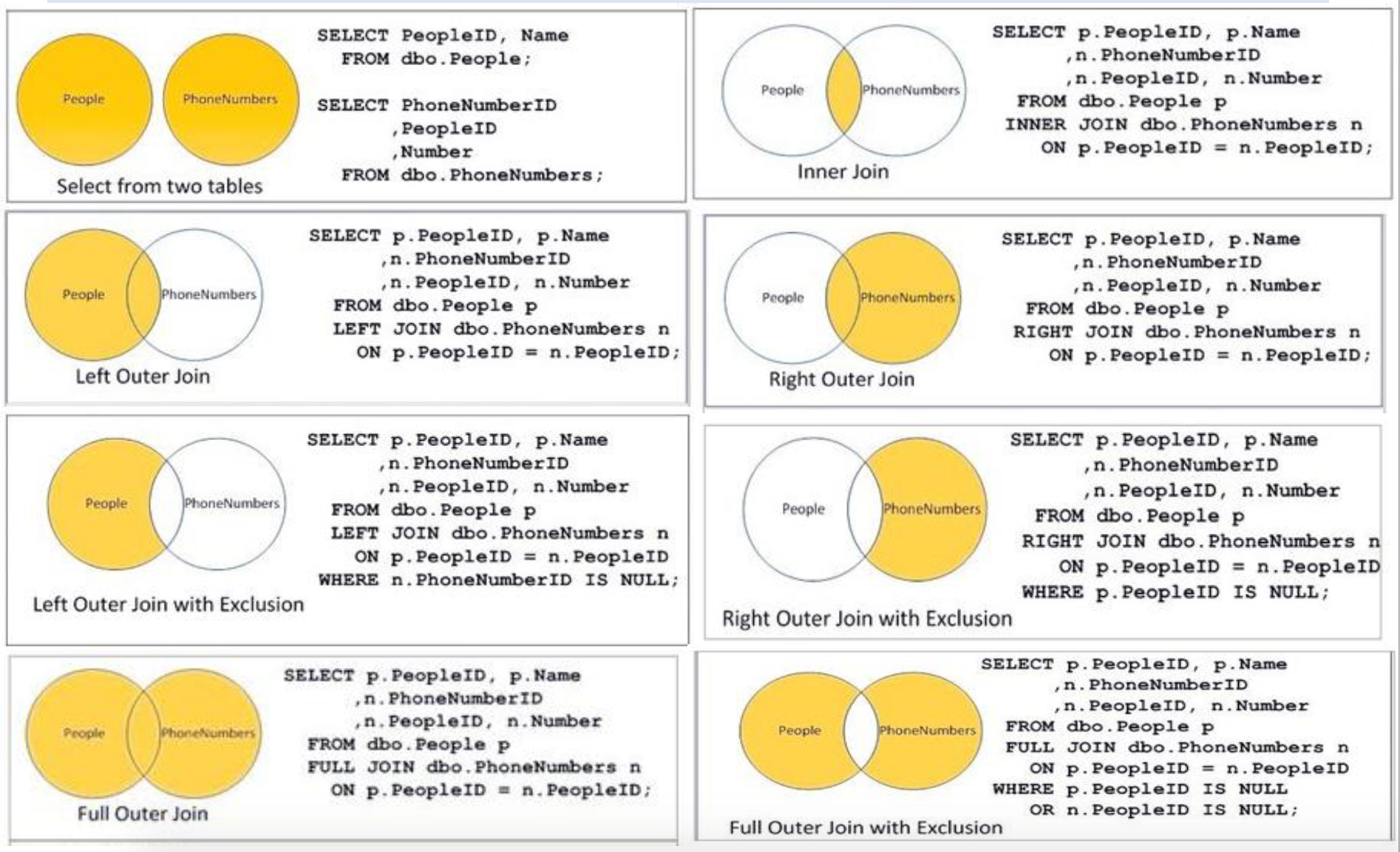
JOIN
Join: Treat > 1 tables in SELECT as a single joined table
★ Inner Join: find “matching” rows
SELECT …
FROM T1 [INNER] JOIN T2 ON <join condition>
WHERE …
NATURAL JOIN on two tables R and S : same column combine together
★ No join condition
–Implicit EQUIJOIN condition for each pair of columns with same name from R and S
• Data type of those columns should match
–No duplicated column names in result set
INNER JOIN v.s. NATURAL JOIN
TableA TableB
Column1 Column2 Column1 Column3
1 2 1 3
The INNER JOIN of TableA and TableB on Column1 will return
a.column1 a.column2 b.column1 b.column3
1 2 1 3
SELECT * FROM TableA INNER JOIN TableB USING (Column1)
SELECT * FROM TableA INNER JOIN TableB ON TableA.Column1 = TableB.Column1
The NATURAL JOIN of TableA and TableB on Column1 will return:
column1 column2 column3
1 2 3
SELECT * FROM TableA NATURAL JOIN TableB
CROSS Join, Multiway join
•CROSS JOIN
★ No join condition
•Multiway join
SELECT …
FROM T1 JOIN T2 ON T1.a = T2.b
JOIN T3 ON T1.c = T3.d
Outer Joins
SELECT …
FROM R { LEFT | RIGHT | FULL } [OUTER] JOIN S ON <condition>
WHERE ...
R LEFT [OUTER] JOIN S
• Return all rows from left table R
• Rows from R may be padded with NULL (columns of S)
R RIGHT [OUTER] JOIN S
• Return all rows from right table S
• Rows from S may be padded with NULL (columns of R)
R FULL [OUTER] JOIN S
•Return all rows from both left R and right table S
•Rows from R and S may be padded with NULL
INNER JOIN ↔ nested query
SELECT ... FROM X INNER JOIN Y ON X.a = Y.b WHERE ...
SELECT ... FROM X WHERE X.a IN (SELECT ... FROM Y WHERE ...)
SELECT ... FROM X WHERE EXIST (SELECT ... FROM Y WHERE X.a = Y.b ...)
Left join ↔ right join
SELECT … FROM T1 LEFT JOIN T2 ON …
SELECT … FROM T2 RIGHT JOIN T1 ON …
Filter in join condition (ON clause) or in WHERE clause?
–INNER JOIN: no difference
–OUTER JOIN:
•filter for right table in LEFT JOIN, or left table in RIGHT JOIN: join condition
–In WHERE would cause issue with NULL value
•filter for left table in LEFT JOIN, or right table in RIGHT JOIN: no difference
Aggregate Functions
★ Summarize info from multiple rows into a single-row value
•Built-in aggregate functions: COUNT,SUM, MAX, MIN, AVG
•used in the SELECT clause or in a HAVING clause
–Ex. SELECT SUM(expr) FROM …
•Discard NULL values from expr(e.g., a particular column)
–COUNT(col) returns # of non-NULL col
–COUNT(DISTINCT col) returns # of unique non-NULL col
★ COUNT(*) returns # of rows including NULL
When empty table, or no row matches WHERE condition
★ COUNT(*), COUNT(col): return 0
★ Other aggregation functions: return NULL
GROUP BY Clause
SELECT … FROM … [WHERE …] GROUP BY <grouping cols> …
• **Partition relation into subsets of rows
–Based on grouping column(s)**
–Provide summary info for each group
•GROUP BY clause
–Specifies grouping columns (>1 is OK)
–Grouping columns may (not must) appear in SELECT clause
•SELECT column list (except columns in aggregation function) is a subset (including empty set) of GROUP BY columns
★ non-grouping columns cannot appear in SELECT clause, unless in aggregation functions
★ SELECT column list: summary information on per group basis
• If NULLs exist in grouping column
–Separate group created for all rows with a NULL value in grouping column
For each project, retrieve the project number, the project name, --and the number of employees from department 5 who work on the project.
select pnumber,pname,count(*)
from project,works_on,employee
where pnumber=pno and ssn=essn and dno=5
group by pnumber,pname;
HAVING Clause
SELECT … FROM … [WHERE …] GROUP BY <grouping cols> … HAVING ...
★ Filter groups (based on group summary info): usually aggregation function
★ vs WHERE which filters rows
For each project on which more than two employees work, retrieve the project number, the project name, and the number of employees who work on the project.
select pnumber,pname,count(*)
from project,works_on
where pnumber=pno
group by pnumber,pname
having count(*)>2;
For each department that has more than five employees, retrieve the department number and the number of its employees who are making more than $40,000.
select dnumber,count(*)
from department,employee
where dnumber=dno and salary>40000 and
dno in (select dno from employee group by dno having count(*)>5)
group by dnumber;
MySQL ISSUE
- CREATE SCHEMA is a synonym for CREATE DATABASE
- EXCEPT not supported
- Work around: NOT IN, LEFT JOIN/IS NULL
- (SELECT a FROM X) EXCEPT (SELECT b FROM Y)
- SELECT a FROM X WHERE a NOT IN (SELECT b FROM Y)
- SELECT a FROM X LEFT JOIN Y ON X.a= Y.bWHERE Y.b IS NULL
- INTERSECT not supported
- Work around: IN, DISTINCT/JOIN
- ★ Faulty implementation (avoid these)
- In GROUP BY, column not in GROUP BY allowed in SELECT
- SELECT a, b, COUNT(*) FROM … GROUP BY a
- Renamed column from SELECT allowed in HAVING
- SELECT a, COUNT(…) AS CNT FROM … GROUP BY … HAVING CNT > 0
- In GROUP BY, column not in GROUP BY allowed in SELECT
Schema Change Statements
DROP
–Used to drop named DB obj, such as tables, views, or constraint
DROP DATABASE [IF EXISTS] dbName;
DROP TABLE [IF EXISTS] tableName;
Alter
- Adding a column
ALTER TABLE COMPANY.EMPLOYEE ADD COLUMN Job VARCHAR(12);
- Dropping a column
ALTER TABLE COMPANY.EMPLOYEE DROP COLUMN Address;
- Changing a column definition
ALTER TABLE COMPANY.DEPARTMENT
ALTER COLUMN Mgr_ssn SET DEFAULT ’333445555’;
- Adding or dropping table constraints
ALTER TABLE COMPANY.EMPLOYEE
ADD CONSTRAINT FK_DnoFOREIGN KEY(Dno)
REFERENCES Department(Dnumber);
Views (Virtual Tables)
– Single table derived from other tables (base tables, views)
–DB object
–Under a schema (container): [schenaName.]viewName
★Virtual table: Not necessarily has persistent data in physical form
Why view?
–To restrict the use of particular columns and/or rows of tables
–To hide the details of complicated queries
–To provide a backward compatible interface
–To restrict the updated/inserted value (WITH CHECK Option)
★ View always up-to-date
–No-persistent data, persistent data
–Responsibility of the DBMS and not the user
•Types
– Regular view: w/o persistent data
Views are virtual only and run the query definition each time they are accessed.
★ Materialized view: w/ persistent data
Materialized views are disk based and are updated periodically based upon the query definition.
Lec 7 : ER-to-Relational Mapping
Step 1: Regular Entity
Create a relation R **that include all simple attributes
–PK: one of key attributes
–R is called entity relation**
• Each tuple represents an entity instance
Tuple − A single row of a table, which contains a single record for that relation is called a tuple.
Relation instance − A finite set of tuples in the relational database system represents relation instance.
Step 2: Weak Entity
Create a relation R that includes all simple attributes
–PK: {PK of owner entity, partial key of weak entity}
**• PK of owner as FK attributes of R
– FK: CASCADE option for ON DELETE or ON UPDATE
If PK of T is (a,b), then FK: S.(a,b) to T.(a,b); separate FKs are not correct
Step 3: Binary 1:1 Relationship
Approach #1: FK approach
–Modify the relation S that is total participation in R
•Include PK of T as FK in S
•Include simple attributes of R in S
Approach #2: merged relation
–If both S and T are total participation, merge S, T, R to one relation
•Approach #3: cross-reference or relationship relation
–Create a relationship relation R (or look up table)
• Include PKs of S and T, as FKs in R
• PK of R: one of the two FKs, and the other is unique
• Cons: extra relation, and JOIN is needed for retrieval
Step 4: Binary 1:N Relationship
★ This cannot be used to map identifying relationship
Approach #1: modify the relation S (N-side of R)
–Include PK of T as FK in S
–Include simple attributes of R as attributes of S
Approach #2: create relationship relation R
–Include PKs of S and T, as FKs in R
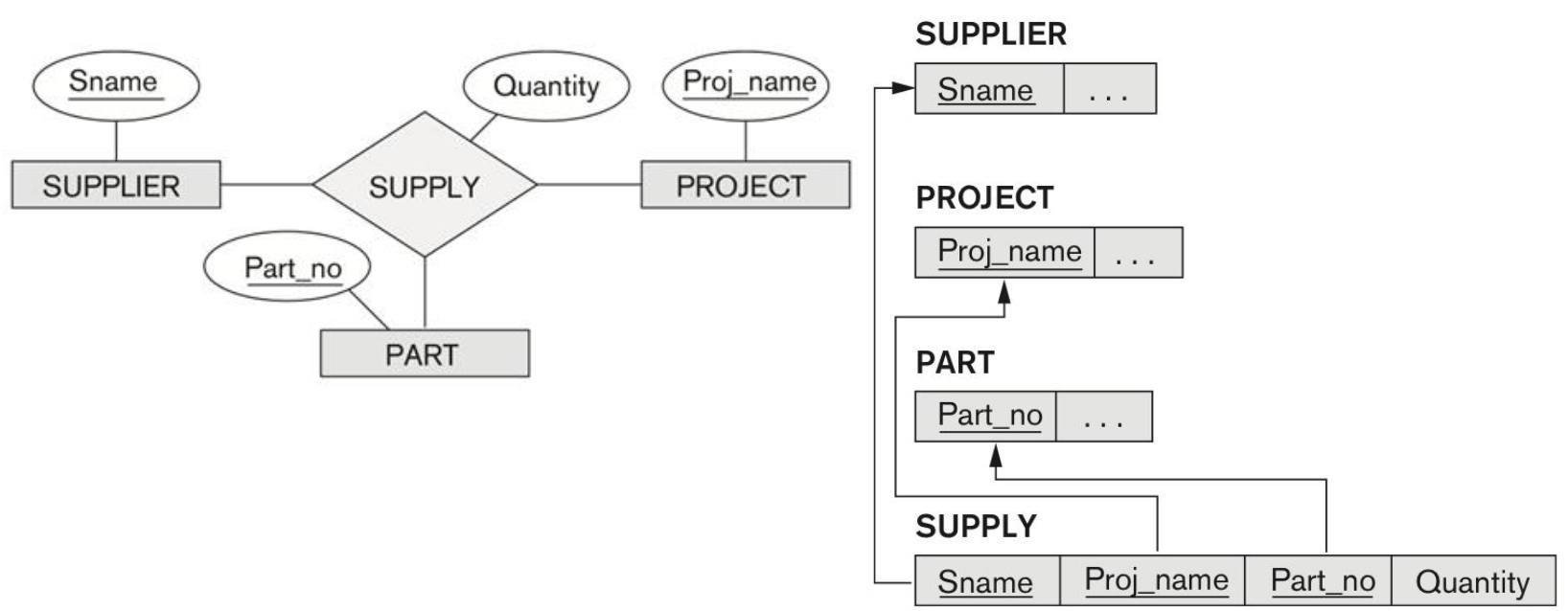
Step 5: Binary M:N Relationship
Create a new relationship relation R
–Include PKs of S and T as FKs in R
•FK propagate (CASCADE) option for ON UPDATE, ON DELETE
–PK of R (composite PK): PK of S, PK of T
–Include any simple attributes of M:N relationship type
–1:1 and 1:N relationships can be mapped to this
Step 6: Multivalued Attributes
Create a new relation R for multivalued attr S.A
–Include attr of A, and PK of S
–PK of S as FK in R
•FK propagate (CASCADE) option for ON UPDATE, ON DELETE
–PK of R: {A, PK of S}
–If the multivalued attribute is composite, include its simple components
Step 7: N-ary Relationship Types
• Create a new relation S **for each n-ary relationship R
–Include PKs of participating entity types as FKs in S
–PK of S: {PKs of participating entity types}
–Include any simple attributes as attributes